
Universal Data Façade (Part 1)
Containment as the Grammar of Data Structure

Data formats evolve as solutions to specific problems. They combine structure and semantics in their own unique way. That’s how we now have many different species of data formats. Each has its strengths and weaknesses. None is universally good, and none is bad in all application cases.
The problem comes when you need to answer a question, where parts of the answer are scattered across heterogeneous data sources. One part of the answer may happen to be in a JSON file, served from an API, another is in an Excel workbook, stored in your drive, and yet others are in Microsoft Word, CSV and XML. This is challenging even when all the files are with the same format, but structured differently.
The problem then is, how to unify structure and semantics from heterogeneous data sources.
This question wraps two other questions: Which universal representation can best carry the information coming from diverse sources, and how to transform different data formats into it?
This is the fourth post in the Containment series.
The answer to the first question is easy: RDF. That’s the only interoperable way of representing data where the semantics do not depend on the structure. Any meaning can be represented with a structure that is always the same: a triple. Unlike tables, for example, where adding another column changes the structure, in RDF, adding a new characteristic about an existing entity or a new entity with a fact about it, is always done by adding a triple. You can’t add just a single entity or a single value. The atomic unit is the triple.
This makes triples are similar to containment. In the same way containment is defined as unity of outside-boundary-inside, a triple is defined by its subject-predicate-object combination.
Bringing several graphs together creates another valid graph. And the use of global identifiers makes RDF graphs self-assembling structures. There are other important benefits of RDF, which I explored in another essay.
The answer to the second question is not so easy. Or at least it wasn’t until recently.
Transforming from a non-RDF to RDF source involves three transformations: transforming identities (from local to URIs), unifying structures (from whatever to a triple), and applying domain semantics (mapping properties and classes from shared ontologies). Initially, all approaches did all three transformations in one stage.
A Brief History of RDFizing
Early transformations began with XSLT in the late 1990s. XSLT is designed to transform one XML structure into another. Though not RDF-specific, it was soon used to convert XML data into RDF/XML by encoding triples within templates. XSLT’s power lies in precise control of XML trees, but it lacks native RDF semantics and becomes cumbersome for complex mappings.
R2RML (W3C Recommendation from 2012) marked the first standard specifically for relational-to-RDF transformation. It defines mappings from relational databases to RDF graphs via declarative rules expressed in RDF itself. Each logical table, column, or join is mapped to RDF subjects, predicates, and objects. R2RML offered formal grounding and interoperability, but it is limited to relational data.
To generalize R2RML’s logic beyond relational sources, the RDF Mapping Language (RML) emerged in 2014 as a community-driven extension. RML extended R2RML, adding support for CSV, XML, and JSON. However, RML can be verbose and performance-heavy for large or dynamic datasets. It requires good knowledge of the data sources and the technologies needed to query them. At the same time, it lacks hash functions, which are essential for constructing deterministic and reliable identifiers.
Around 2017, SPARQL Generate appeared. It extends SPARQL with GENERATE, SOURCE, and ITERATOR clauses to create RDF from diverse input formats such as JSON, CSV, XML, or HTML. Its logic unifies querying and transformation within a single syntax, offering strong expressive power and dynamic control, yet relying on custom extensions not part of the SPARQL standard.
All these approaches perform the transformation of identity, structure and semantics in one stage.
In 2018, OTTR (Reasonable Ontology Templates) shifted focus from mapping to portable templating. It defines parameterized RDF graph templates that can be expanded into concrete RDF structures. Rather than linking to input formats, OTTR standardizes reusable RDF pattern generation, promoting consistency, maintainability, and reusability. It does not handle data extraction directly (works on RDF), but the tools that support it do that, and in this way, separate the stage of generic identity and structure creation from applying domain semantics.
Then in 2021 SPARQL Anything appeared. It introduced a minimalistic model Façade-X, that presents any data structure as RDF, which can then be manipulated with native SPARQL. Importantly, it does so without extending SPARQL and without requiring experience with the source structure.
Façade-X demonstrates that what is common to all structures is, yes, you guessed it, containment.
All data is structured as nested containers
A Word document contains headings containing paragraphs, bullets, tables and images. An Excel workbook contains spreadsheets containing cells. A PowerPoint slidedeck contains slides, containing titles, text, bullets, hyperlinks and images. An XML file contains elements containing attributes, text nodes, and other nested elements, forming a hierarchical tree structure defined by tags. A JSON file contains objects containing key–value pairs and arrays, which in turn contain other objects, arrays, or primitive values such as strings and numbers.
Façade-X interprets every data source as a container, containing key-value pairs. The keys are either generic containment relations or specific RDF properties. The values are either other containers or literals (strings, numbers, dates etc).
Let’s start with the primitive case, a CSV consisting of a single row with the following values: mathematician, philosopher, logician, physicist.
Façade-X will see it as a container, containing one key value pair, the value of which is another container, containing four key-value pairs, the values being the four words. All keys in this case will only indicate order.
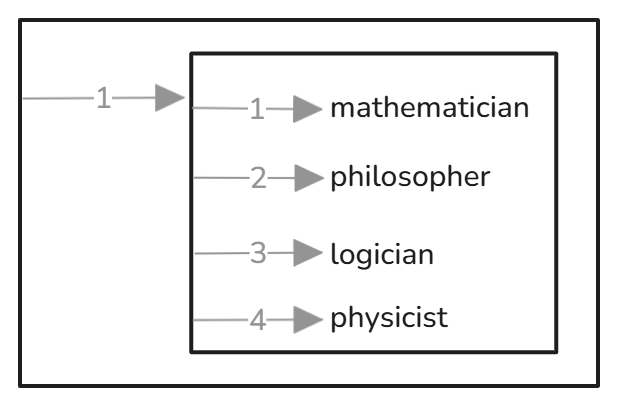
Next, a more complicated CSV:
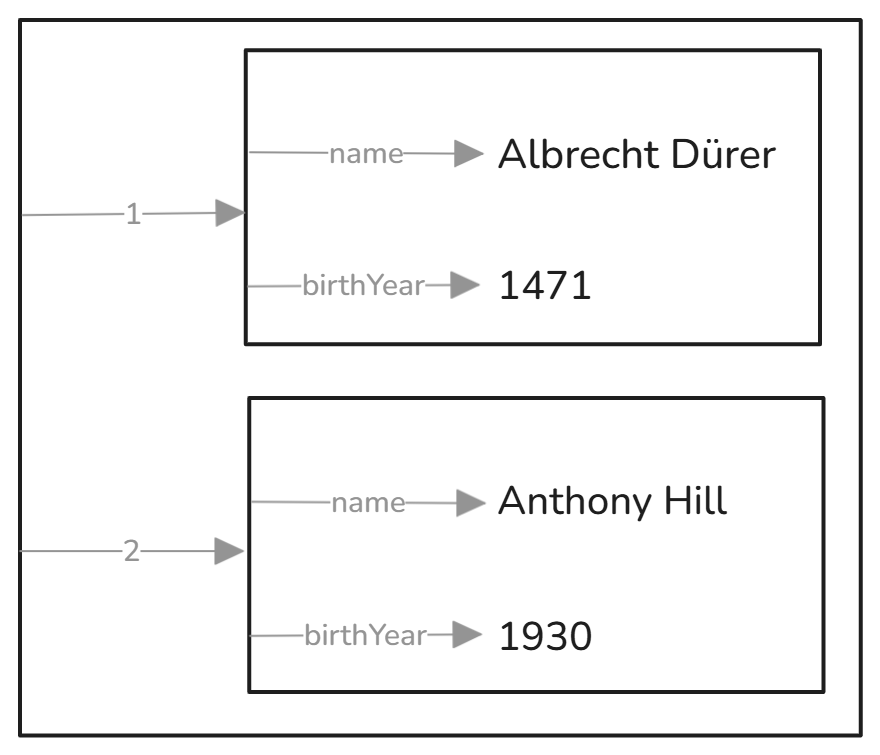
name,birthYear
Albrecht Dürer,1471
Anthony Hill,1930
Every CSV file is an ordered sequence of records where each record is an ordered sequence of values. The first record in this example contains headers. Façade-X (SPARQL Anything) has a parameter telling it if the table has headers. Then it will see this CSV as a container containing two containers, each containing key-value pairs with keys, constructed from the headers and values, the respective fields. Here’s how this looks:
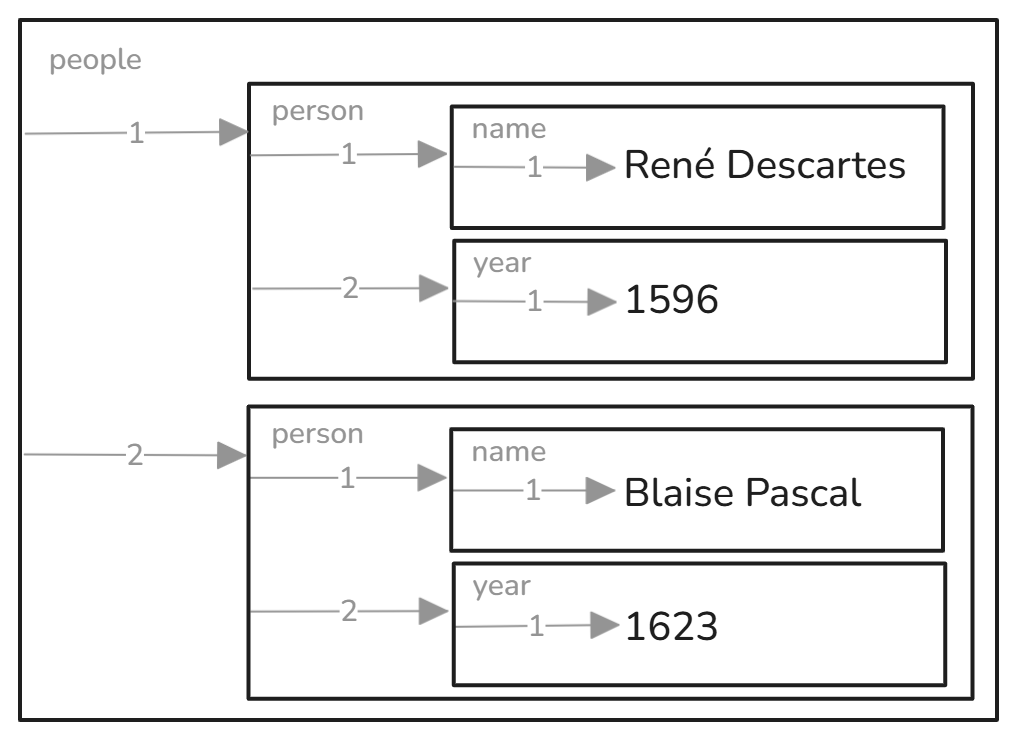
Now let’s have a similar structure, in XML, but a bit more expressive:
<people>
<person>
<name>René Descartes</name>
<birthYear>1596</birthYear>
</person>
<person>
<name>Blaise Pascal</name>
<birthYear>1623</birthYear>
</person>
</people>Façade-X will see this as the following RDF
@prefix xyz: <http://sparql.xyz/facade-x/data/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix fx: <http://sparql.xyz/facade-x/ns/> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
[
rdf:type fx:root ;
rdf:type fx:people ;
rdf:_1 [rdf:type xyz:person ;
rdf:_1 [rdf:type xyz:name ;
rdf:_1 “René Descartes”] ;
rdf:_2 [rdf:type xyz:birthYear ;
rdf:_1 “1596”]
] ;
rdf:_2 [rdf:type xyz:person ;
rdf:_1 [rdf:type xyz:name ;
rdf:_1 “Blaise Pascal”] ;
rdf:_2 [rdf:type xyz:birthYear ;
rdf:_1 “1623”]
]
] .
Using blank nodes is optional, but the square brackets beautifully show the containers and how they are nested. There is one outer container. To distinguish it from the rest it is typed fx:root. In this case it is also typed as fx:people, an URI constructed from label of the respective source XML container.
Now we have three levels of nested containers, all of them typed.
Let’s use the list we started with and include it in the structure. This time, let’s render that in JSON.
[
{
“name”: “Alfred North Whitehead”,
“occupations”: [”mathematician”, “philosopher”, “logician”, “physicist”],
“birthYear”: 1861
},
{
“name”: “Anthony Hill”,
“occupations”: [”artist”, “mathematician”],
“birthYear”: 1930
}
]From this input, Façade-X, with the help of SPARQL Anything, will produce the following RDF:
@prefix xyz: <http://sparql.xyz/facade-x/data/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix fx: <http://sparql.xyz/facade-x/ns/> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
[
rdf:type fx:root ;
rdf:_1 [xyz:name “Alfred North Whitehead” ;
xyz:birthYear “1861”^^<http://www.w3.org/2001/XMLSchema#int> ;
xyz:occupations [rdf:_1 “mathematician” ;
rdf:_2 “philosopher” ;
rdf:_3 “logician” ;
rdf:_4 “physicist”]
] ;
rdf:_2 [xyz:name “Anthony Hill” ;
xyz:birthYear “1930”^^<http://www.w3.org/2001/XMLSchema#int> ;
xyz:occupations [rdf:_1 “artist” ;
rdf:_2 “mathematician”
]
] .
]
Which, as a visual graph, looks like this:
where _:b1 to _:b5 are local densifiers of the same blank nodes, which in Turtle are represented with [ ]. The same structure, shown as nested containers, will look like this:
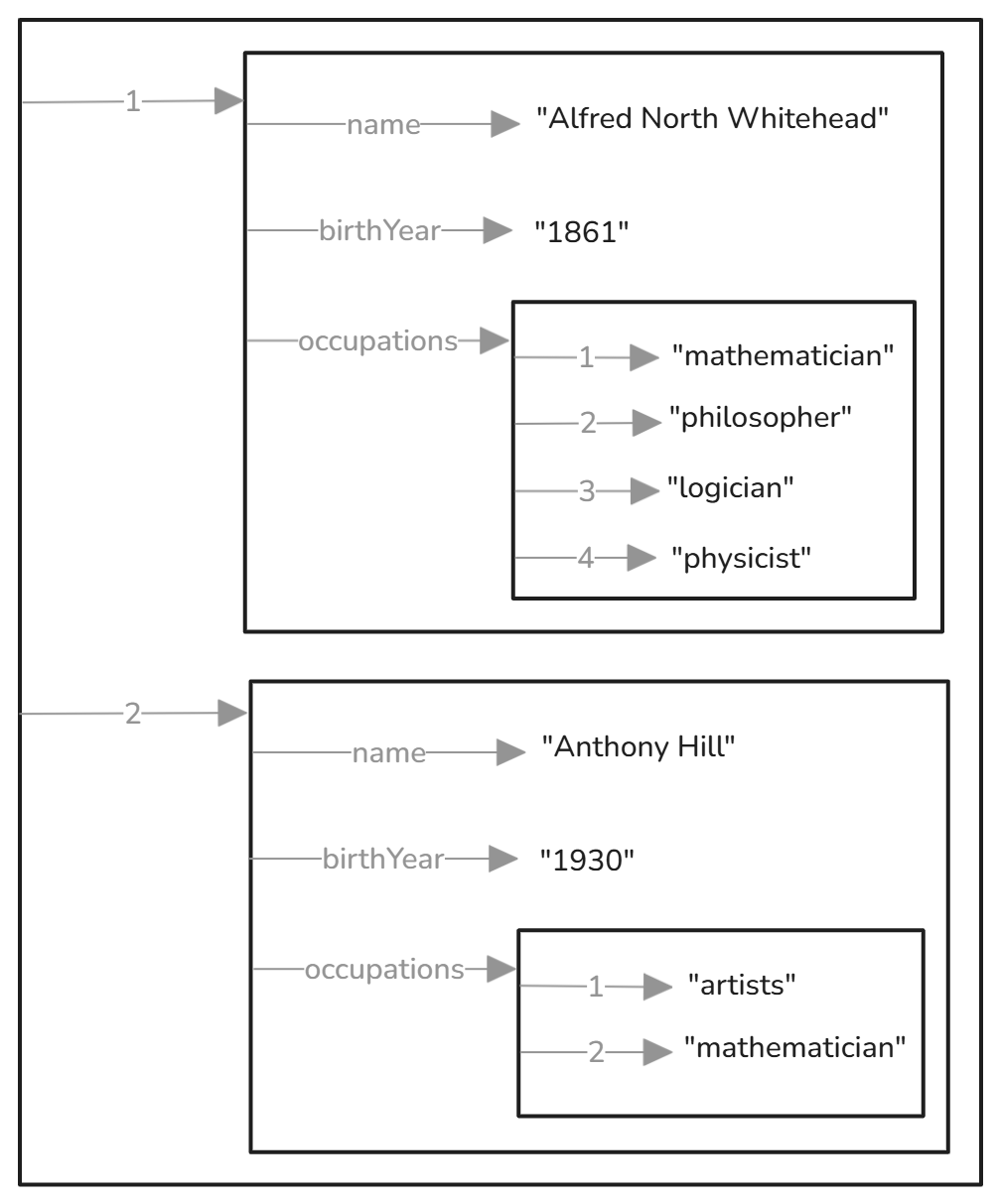
It turns out that every data structure is a container that holds one or more containers, which can be optionally ordered and typed. Each container indicates an optionally typed boundary and can contain zero or more nested containers of the same kind. The deepest level contains one or more literals.

Will that hold for all structures? So far, it has worked with CSV, XML and JSON. But what about HTML or MS Word? Or PowerPoint. We’ll see that in Part 2.