
Graph Pruning (Part 2)
Technicalities

What does it take for a pruning routine to turn your personal knowledge graph into a reliable serendipity generator? Two conditions are certain. First, you need a lush digital garden where you spend significant time. Second, you need to experiment with graph pruning until you find the right quantity and frequency. Yet, these conditions may not be sufficient. Another important factor is that your daily note page, independently from the pruning fragment, brings a sufficient amount of surprise every day. The surprises may come from notes sent from the past and from other semi-random workflows.
In part 1 I forgot to mention that the pruning smart blocks are not the only ones pulled randomly into my daily note page (DNP). Another set of such random blocks is that for future actions.
Things can be done only at present. The “later” is simply a future present. It’s always now and never later, so items marked to be done later never get done. They pile up.
I don’t have a “later” tag as such, but some things I capture with my phone I tag with the more specific #toCheckOut, #toRead, #toWatch, and #toShare. These tags are also classes in the RIO ontology and are included in the TODO trigger list. I’ll explain the latter in a minute. Sometimes, I might check such items in case of unexpected waiting, but that was rare and did not prevent blocks tagged this way from piling up. Until I decided to configure my daily Smart Block to randomly pull one such item a day on different days of the week. For example, when quickly capturing something of interest that I don’t have the time to look at right now, it gets tagged with #toCheckOut. If it’s related to what I’m working on, I tag it with that project or with a date. In all other cases, I don’t think about it, knowing that it will appear on a DNP someday. That doesn’t mean I would actually spend time doing it. It is only a suggestion. If I toggle TODO for that block, only then it means I plan to check it out on that day. Since it is in the TODO trigger list, the DONE state automatically turns the tag into #Checked and, respectively, #Read, #Watched, and #Shared so that, once processed, such blocks never get pulled in the DNP anymore.
Blocks marked #toShare are those that capture things I found interesting to share but did not do that right away for some reason. If not specified, they get scheduled in Buffer to go to Bluesky, Mastodon, and X-twitter. If specified to share with a particular person or group of people, they get that reference and get shared whenever they resurface, either randomly brought in a DNP or when I meet with those people and check for items I had noted for them.
I stopped using the #toRead random smart block when I started using Readwise Reader. Speaking of Readwise, two random smart blocks bring annotations from books and articles and bookmarked (previously liked) tweets. That latter part proved to be serendipitous by reviving years-old conversations in new contexts and attracting new people to join the discussion. Such a way of using Twitter was additionally supported by the Twemex extension, later acquired by Tweed Hunter.
Now, before getting to the scripts and the queries, I have one more thing to share. I slightly modified my graph pruning practice. It happened while I was writing the first part, and that’s why it wasn’t mentioned there. It's now too early to report any experience with this change, but I hope it will bring more serendipitous events of the path pattern since they will be related to people.
The most important entity type in my graph (I guess in most PKGs) is Person. Once such a page is created, it is referred to in blocks about meetings, questions to ask and other talking points, tasks, issues, recommendations, or anything else I learned via that person. They are also tagged in videos, blocks about something promised, and many more. However, entities representing people also come in via Zotero and Readwise as authors of papers, articles, and books or from Wikidata via SPARQL import queries. This way, my graph gets filled with both people I know and people I just know of. To distinguish them, I recently created a new class in RIO, “I know.”
In case, at some point, I need also “I know of,” and if I keep using “I know” in the sense I know directly, then I may consider declaring "I know" as a subclass of “I know of.”
The main reason I created "I know" is that I'm interested in having the intersection of the classes "Person" and "I know" handy.

I have a template and smart blocks with the combination, so when I apply them or add an "I know" page reference in the type declaration block next to "Person," I get, for example:
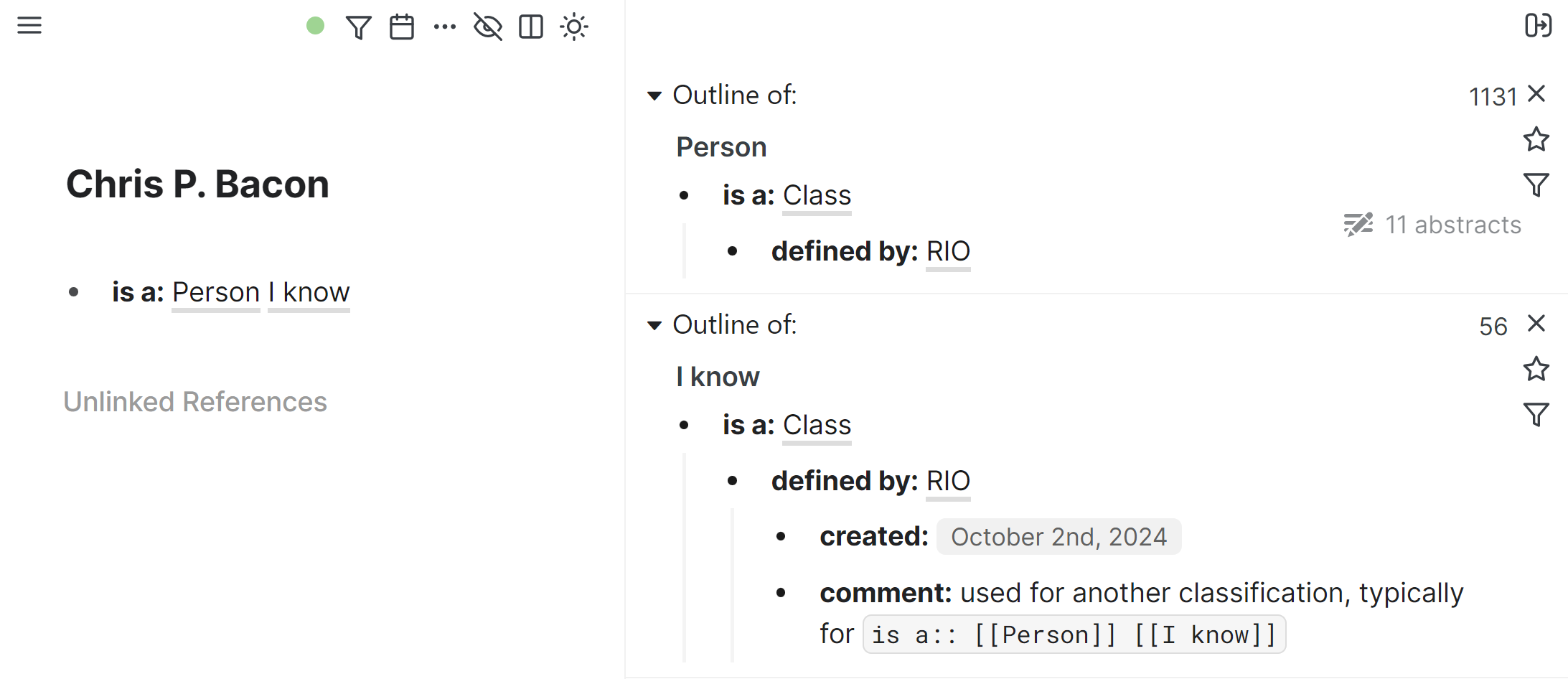
In the example, Chris P. Bacon is a member of both classes, and their labels form a natural sentence: Chris P. Bacon is a person I know.
So now my graph pruning block brings three sets of random pages: one from all pages, one from non-typed and one from those typed “Person” for review if they also need "I know" typing.
I'll now go through the scripts and queries I use for graph pruning. I'll go gently so that non-technical Roam users who want to give a try, would be able to replacate all steps. I also hope that users of other tools would be able to transfer these ideas. There were already a few people that reached out to say that they are applying my ideas on other PKM tools.
Scripts and queries

The following extensions are used in the current implementation of graph pruning:
Smart blocks
Query Builder
Todo Trigger (optional)
Time tracker (optional)
All you need to do is go to Roam Depot and enable them. If you want to use graph pruning with vanilla Roam without any extensions enabled, you can do that, too. I’ll share that method at the end.
If you are not using a daily workflow already, you have to enable it by giving it a name, in my case, “Daily”, and set when to run. I have also enabled the option to Run only on this device to avoid multiple runs on the same day. Of course, the content will be synced with all devices.
The child block of the Daily smart block that brings the pruning set looks like this
<%IFDAYOFWEEK:1,2,3,4,5%><%SMARTBLOCK:Graph pruning%>It simply triggers the Graph pruning smartblock on certain days of the week. I started with 1, 3, 5, which means Monday, Wednesday and Friday but now, as you see, I made it run every day of the work week.
The graph pruning smart block looks like this:
- #SmartBlock Graph pruning
- Graph [[pruning]]:
- Number of pages:#.self-destruct **((zZ_o7AviM))** of which typed: **((cv2_pu_a2))**
- <%SMARTBLOCK:Not typed pages%>
- <%SMARTBLOCK:Pages to process%> The first child is for the counters. I used to have them on separate blocks, as I showed in the previous post, but now they are in the same block. The other difference is that I now use reference of the blocks, where I keep the Datalog queries. The content of ((zZ_o7AviM)) is a reference of the following block:1
:q [:find (count ?page) .
:where
[?page :node/title]]which counts the number of pages in the graph.
The second block reference ((cv2_pu_a2)) is of a block that counts the number of pages typed with classes using the RIO ontology:
:q [:find (count ?page).
:where
[?isAclassRef :node/title "is a"]
[?classRef :node/title "Class"]
[?rioRef :node/title "RIO"]
[?definedByRef :node/title "defined by"]
[?page :node/title]
[?typeChild :block/parents ?page]
[?typeChild :block/refs ?isAclassRef]
[?typeChild :block/refs ?class]
[?class :block/children ?isAblock]
[?isAblock :block/refs ?isAclassRef]
[?isAblock :block/refs ?classRef]
[?defByblock :block/parents ?isAblock]
[?defByblock :block/refs ?definedByRef]
[?defByblock :block/refs ?rioRef]
]This may look complicated, and indeed, you can use a simpler one, which I’ll show in a minute. But, ignoring the syntax, it might be worth seeing it visually as the graph pattern it represents:
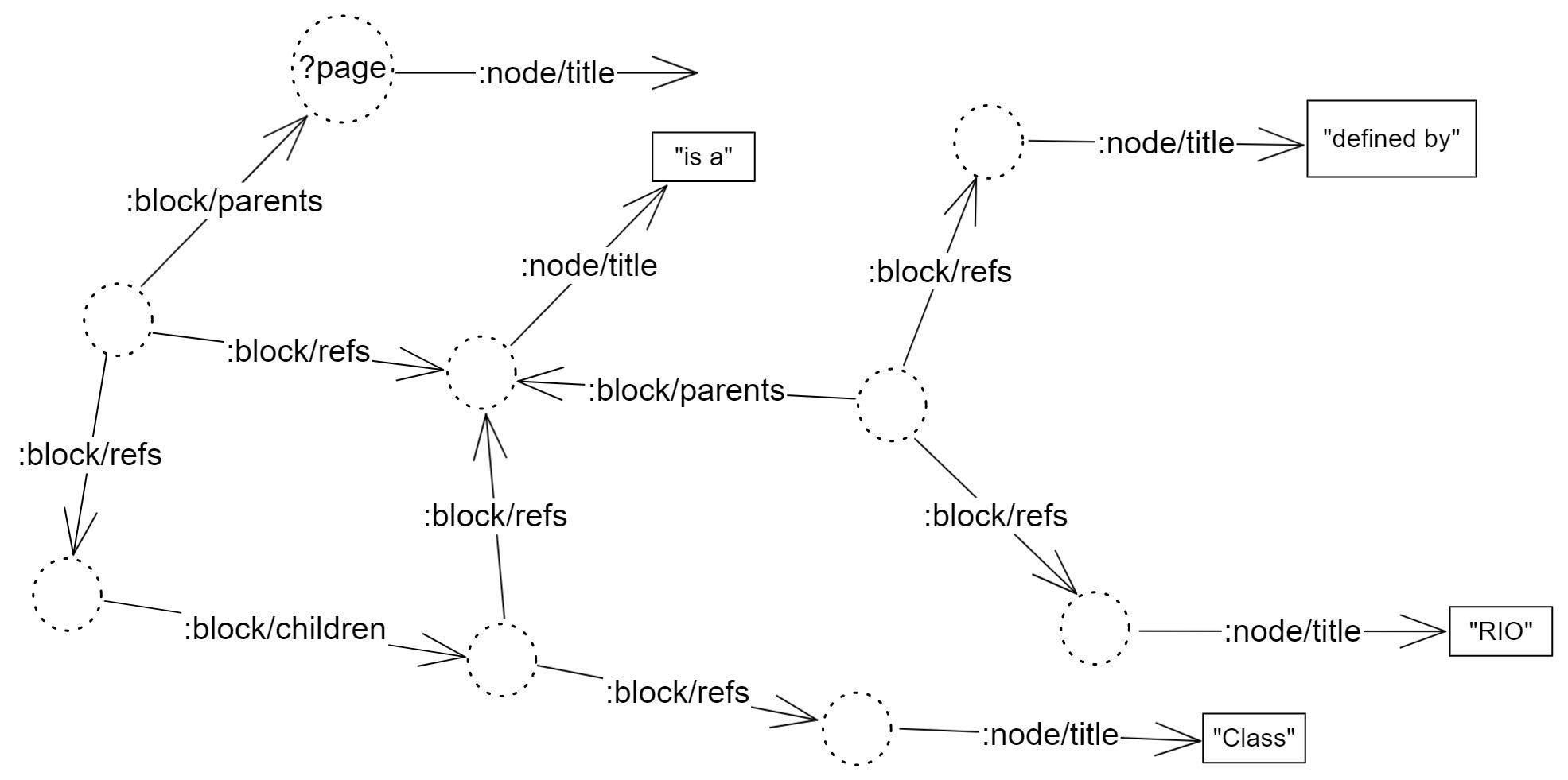
A more direct access to the graph stimulates graph thinking, and that brings numerous benefits, as I wrote elsewhere. Even non-graph tools, like GitHub and GitLab can be used as graphs and that can enlarge their typical scope to cover more project management and governance needs. But let’s not deviate. My point is that you can just copy/paste the Datalog query or look at it as a graph pattern to get more insights about your personal knowledge graph.
Now, here is the promised shorter query to count typed pages:2
:q [:find (count ?page).
:where
[?isA :node/title "is a"]
[?page :node/title]
[?page :block/children ?child]
[?child :block/refs ?isA]
]If needed, replace “is a” with your attribute for type declaration, for example:
[?isA :node/title "type"]This query assumes the type declarations are always in the root block. That wasn’t the case with my original counter, where it could be at any level on the page:
[?typeChild :block/parents ?page] The reason for that is the way I configured my Readwise export:
{{full_title}}
is a:: {% if category == "books" %}#Book{% elif category == "articles" %}#Article{% elif category == "tweets" %}#Tweet{% elif category == "podcasts" %}#Podcast
{% endif %}
by:: [[{{author}}]]
{% if document_tags %}has topic:: {% for tag in document_tags %}#[[{{tag}}]] {% endfor %} {% endif %}
{% if url %}URL:: {{url}} {% endif %}
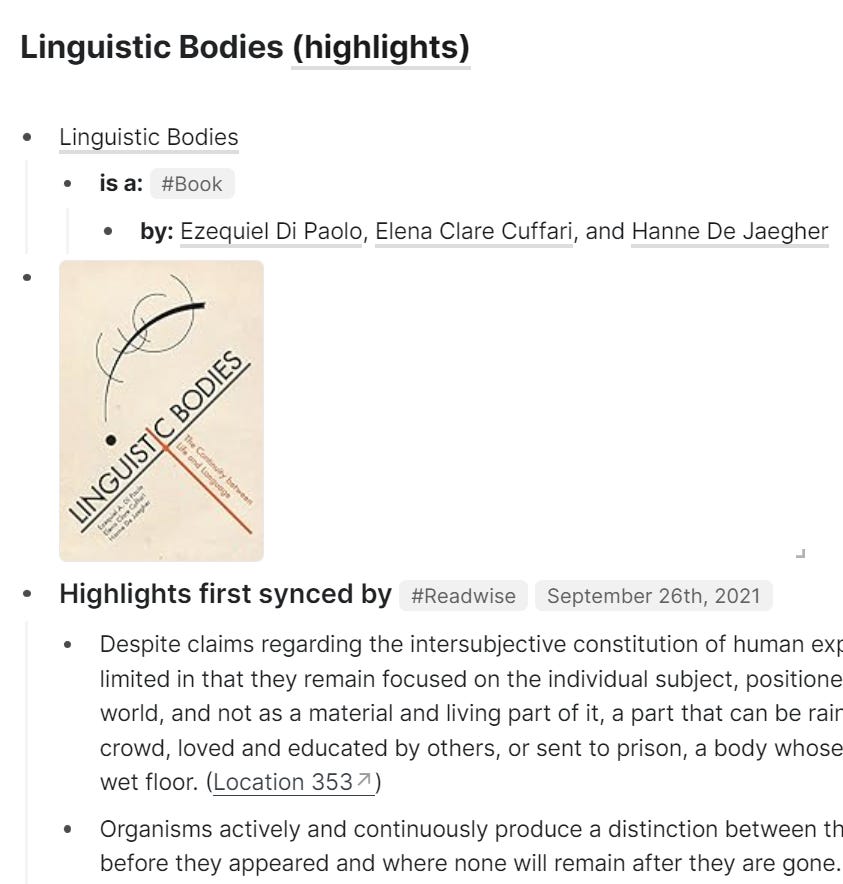
{% if image_url %} {% endif %}Although the page that is created in Roam is a set of highlights and, as such, does itself represent the annotated book or article, the fact that it contains a type declaration at block level for the source of these highlights is sufficient for me to consider the page typed without adding a root declaration such as “Annotation set.” Here is an example where the imported highlights were from a book that already had a page that I liked, but generally, the typing will only refer to the first block in the annotations page, the one created by Readwise with [[(highlights)]] in the title.
Now, let’s see the two smart blocks that pull random pages.
