
Universal Data Façade (Part 2)
Some more complex structures now

Façade-X is a way to represent any data source as an RDF graph. What all data structures share is that they can be seen as nested containers. The reference implementation of Façade-X is called SPARQL Anything. To query or transform any source structure, all you need is to know SPARQL. Once you do, you can SPARQL anything.
SPARQL is easier than you think. Thinking in containers helps there as well, as I showed elsewhere . And if you are not interested to learn it, lazy, or in a hurry, LLMs know SPARQL, so they can help you.
Façade-X can be (and is) used to unify the files you work with, so you can get a powerful personal knowledge graph. It can be (and is) used at the corporate and multi-organizational level to unify and integrate data, and unlike proprietary alternatives, without creating technical debt and at no cost.
It has now been four years since the paper introducing X-Façade was published. In the meantime, the reference implementation SPARQL Anything, built by the leading authors of that paper, Enrico Daga and Luigi Asprino, is already capable of applying Façade-X on over a dozen different file formats.
This is the second part on Façade-X (and the 5th post in the Containment series ). In the previous part, I went through several examples to show how different structures are interpreted in a unified way.
It turns out that every data structure is a container that holds one or more containers, which can be optionally ordered and typed. Each container indicates an optionally typed boundary and can contain zero or more nested containers of the same kind. The deepest level contains one or more literals.

The examples in the previous post were with CSV, XML, and JSON. These are formats for structured data. But about unstructured data?
Most of the unstructured data today is published as HTML. If Façade-X can unify it, then mixing data from CSV, XML, and JSON would be trivial.
The Graph Façade of HTML
Recently, I published a simple HTML page with links to my slide decks, scattered in different places. I’ll use this page as an example.
Running this generic construction query on it
PREFIX fx: <http://sparql.xyz/facade-x/ns/>
CONSTRUCT {?s ?p ?o}
WHERE {
SERVICE <x-sparql-anything:> {
fx:properties fx:location “https://kvistgaard.github.io/slides/” ;
fx:media-type “text/html” .
?s ?p ?o
}
}
will generate a graph of 241 triples, which looks like this
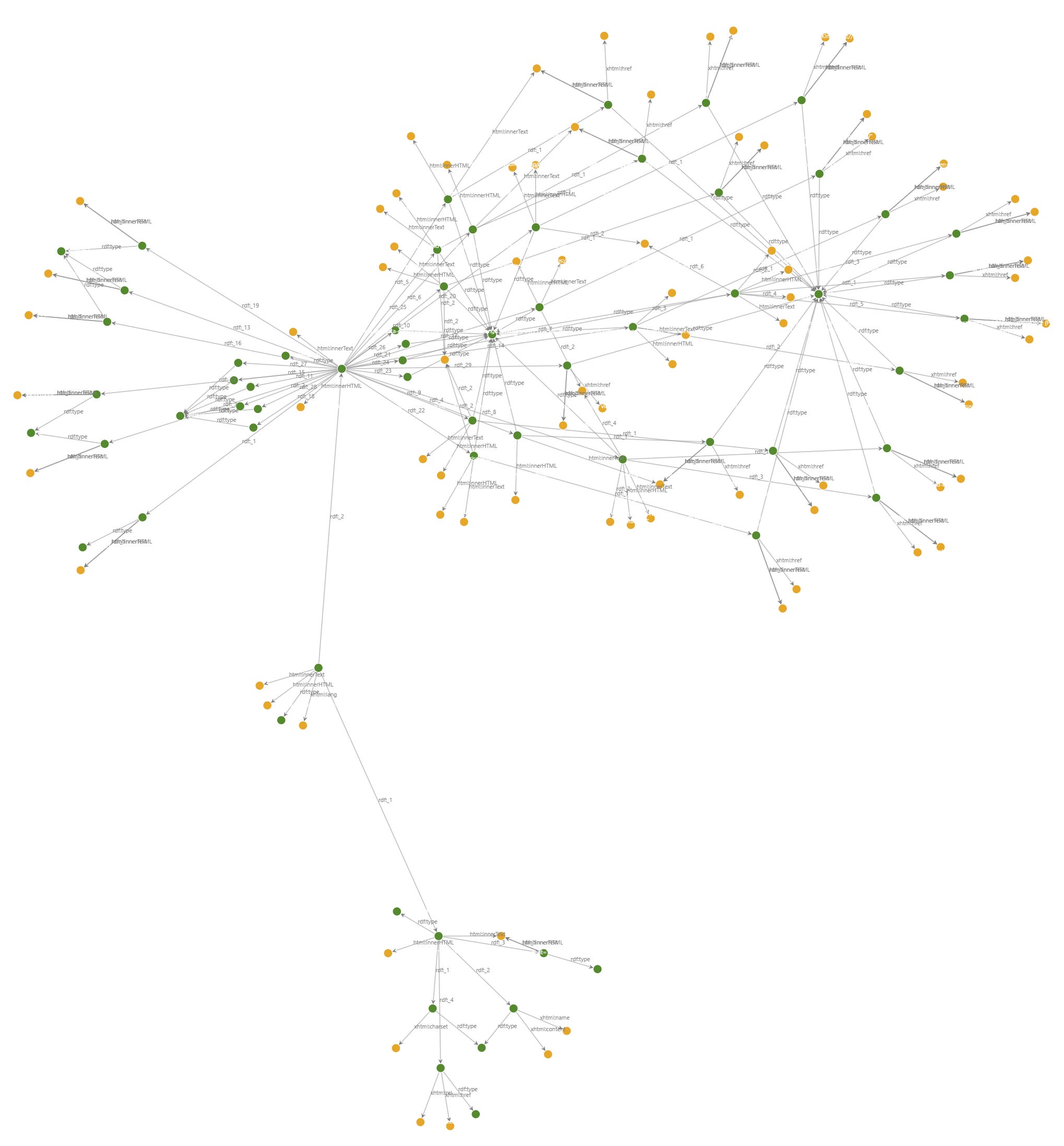
How come an HTML of less than 30 visible lines of hypertext produces so many triples? Well, it turns all elements into a graph and there are plenty, even in this small page.
Let’s see how many types of containers there are and their instances.
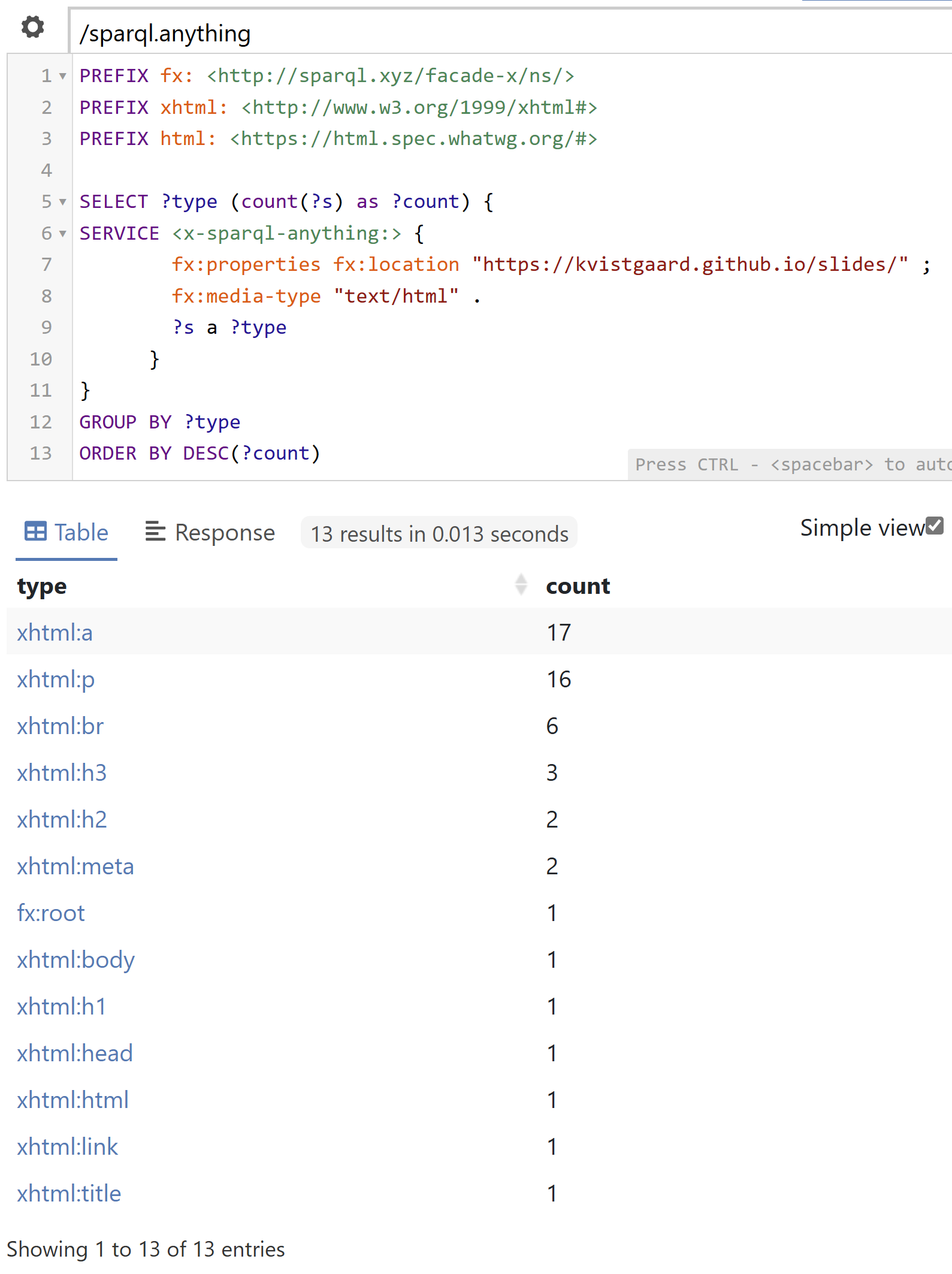
So there is one Heading1, two Heading2, three Heading 3, 16 paragraphs and 17 hyperlinks.
Now we can ask all kinds of questions. As an illustration of one such question, let’s get all the visible content ordered, with the format type, paragraph or heading, and all hyperlinks.
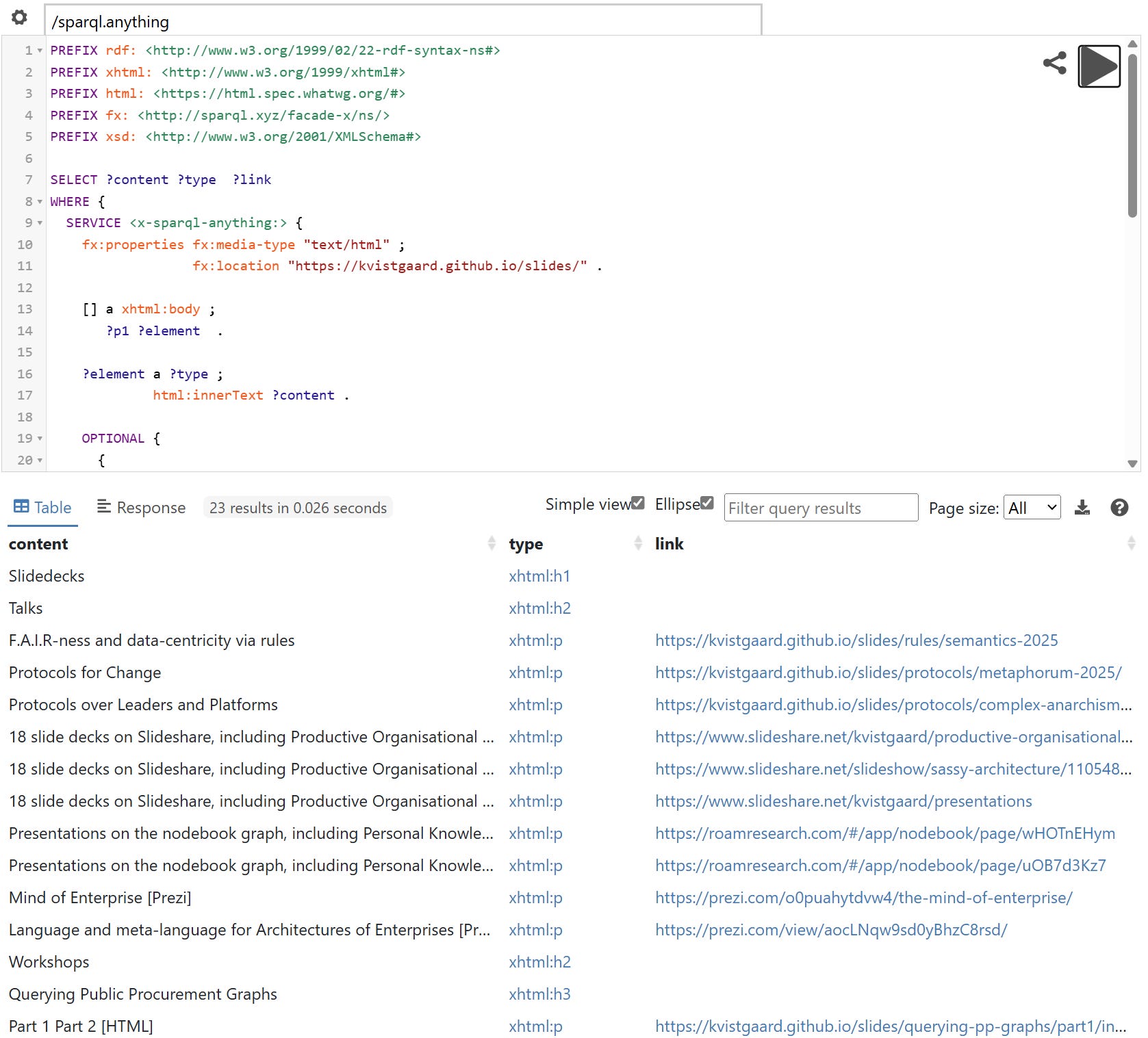
This query is a bit more sophisticated because it uses relative hyperlinks, as some of the slide decks are HTML pages stored in the same repository as the page with the collection of links. At the end of the post, there will be a section with step by step guidance for those who want to reproduce these examples.
So far, we used CSV, XML, JSON and HTML. All these formats are different, and yet they have something in common: they are open standards. Sadly, a lot of information is locked in proprietary formats. And the majority of those happen to be formats of Microsoft. Can Façade-X help there?
Modelling the Mazes of Microsoft
To start with, Excel is an obvious choice. First, in case this needs reminding, there is a global dependence on Excel.
And second, it will be easy to compare with the CSV, XML and JSON examples from the previous part.
The example data there was not random. All these people are polymaths. The other thing they have in common is that they are all known mathematicians. Some of them are also known for their work as philosophers, and others as artists. They are now all in one Excel workbook, in two separate worksheets

Façade-X distinguishes between a resource and a data source. A resource contains a data source, which contains one root container. In all previous cases, we had the file name as the resource. Façade-X turns that file name into a named graph identifier, containing the data source, the root container, containing everything else. If we look at what is generated not as triples but as quads, then the fourth element of each quad will be the named graph. If we take the first CSV and ask for the graph, we’ll get this:
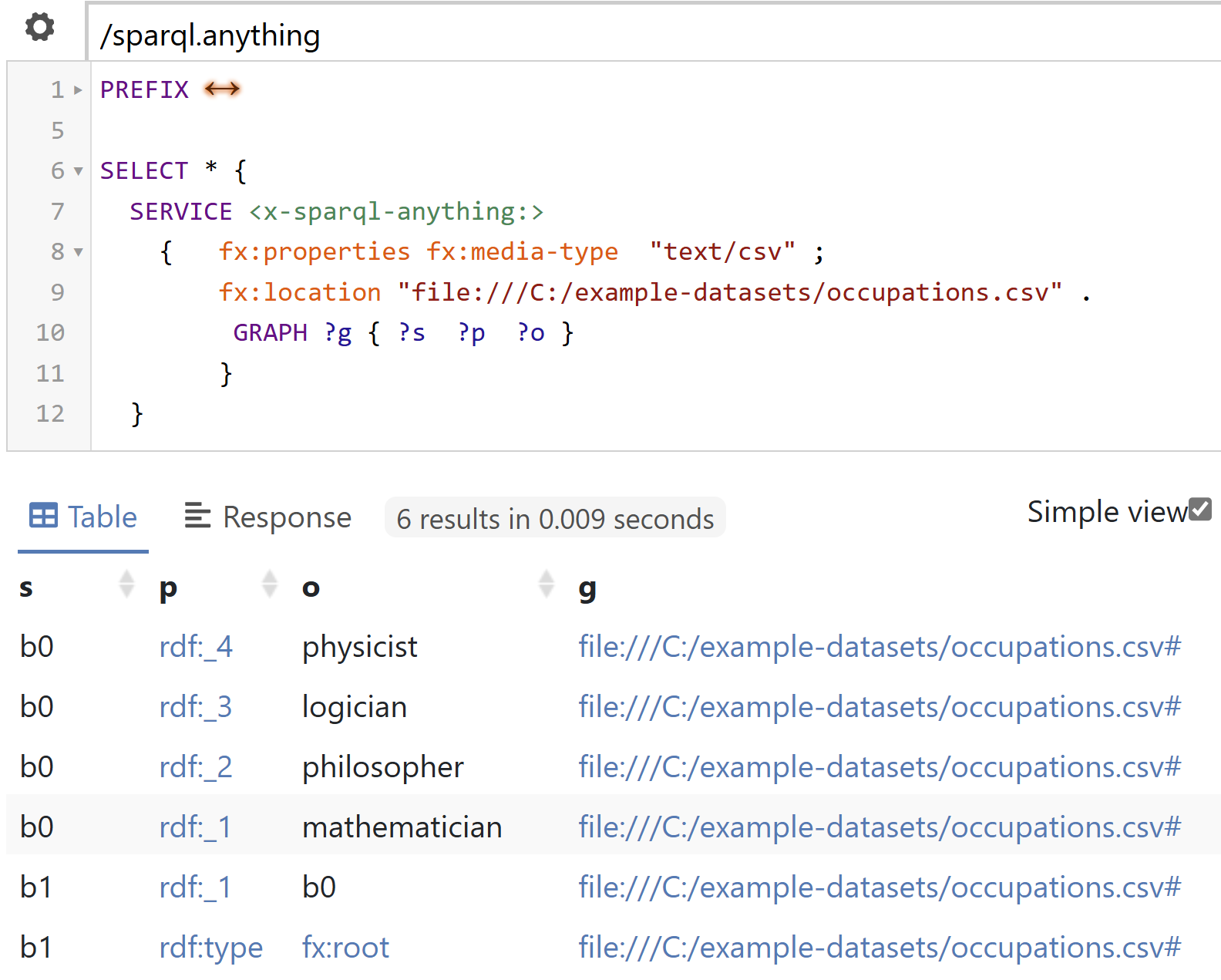
It can be read as: subject-predicate-object-context.
But if we do that on an Excel workbook, we get something more interesting.
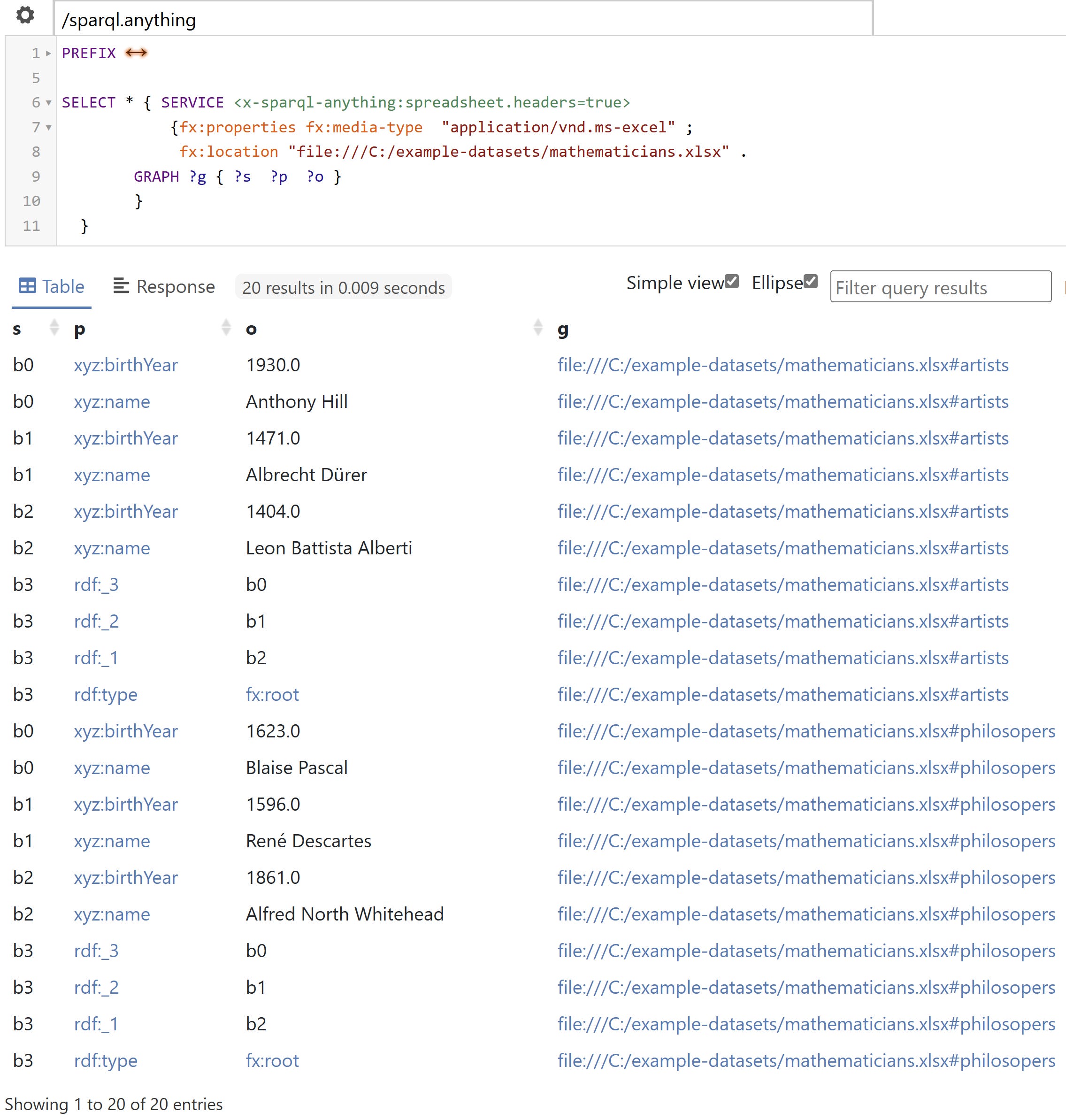
The resource we query is partitioned into two resources, which Façade-X will interpret as two named graphs. Each of them contains a data source — the root — which contains the triplified content of each spreadsheet. Here is the resulting graph TriG format, where the containment structure will be easier to see:
@prefix xyz: <http://sparql.xyz/facade-x/data/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix fx: <http://sparql.xyz/facade-x/ns/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
<file:///C:/example-datasets/mathematicians.xlsx#artists> {
[ rdf:type fx:root .
rdf:_1 [ xyz:birthYear “1404”^^xsd:int ;
xyz:name “Leon Battista Alberti” ] ;
rdf:_2 [ xyz:birthYear “1471”^^xsd:int ;
xyz:name “Albrecht Dürer” ] ;
rdf:_3 [ xyz:birthYear “1930”^^xsd:int ;
xyz:name “Anthony Hill” ] ;
]
}
<file:///C:/example-datasets/mathematicians.xlsx#philosophers> {
[ rdf:type fx:root .
rdf:_1 [ xyz:birthYear “1861”^^xsd:int ;
xyz:name “Alfred North Whitehead” ] ;
rdf:_2 [ xyz:birthYear “1596”^^xsd:int ;
xyz:name “René Descartes” ] ;
rdf:_3 [ xyz:birthYear “1623”^^xsd:int ;
xyz:name “Blaise Pascal” ] ;
]
}
We got this containment pattern: { [ [ ][ ][ ] ] }.
Next up is Word. Similar to HTML, it contains a sequence of headings, paragraphs and other elements such as bullets and tables.
What is more interesting, and sets MS Word apart, are the comments. Interestingly, MS Word has been notoriously bad at extracting comments, and I often use SPARQL Anything to get them out.
Façade-X sees each comment as a container, containing containers with the comment author, the comment text, and the thread number. In the last section, I’ll share the query that will get the comment, the text of the comment, and the comment author.
Next up is PowerPoint. A PowerPoint slide-deck contains sections (optionally), containing slides, with their title and other content. I’m rarely using PowerPoint for workshops and conference presentations anymore, but I still use it for my training courses. These course materials are full of hyperlinks. And getting them together with their slide and what object they were on, used to be a challenge. PowerPoint itself offered no help for that. And today, in 2025, there is no out-of-the-box way to do that.
You may ask, what about Copilot? It’s useless so far.1
And what about Claude Code? I tried today to get the links with it. The initial answer was wrong. After some minutes and tokens spent and kWh energy consumed, it finally got it right, and produced a CSV listing the hyperlinks and on which slide or speaker note they are.
Yet, SPARQL Anything does it right away, reliably, efficiently and even the query needed is very short.2
One query, many quarries
SPARQL queries RDF graphs exposed via a SPARQL endpoint. But importantly, one query can get and combine data from several independent endpoints. SPARQL Anything extends the use of the SERVICE clause so that the address of each resource becomes an endpoint that can be queried, be that in your file system, or somewhere on the web.
But what about REST APIs?
Here’s an example of a query getting the issues from one the repositories of the Model Content Protocol using the GitHub API:
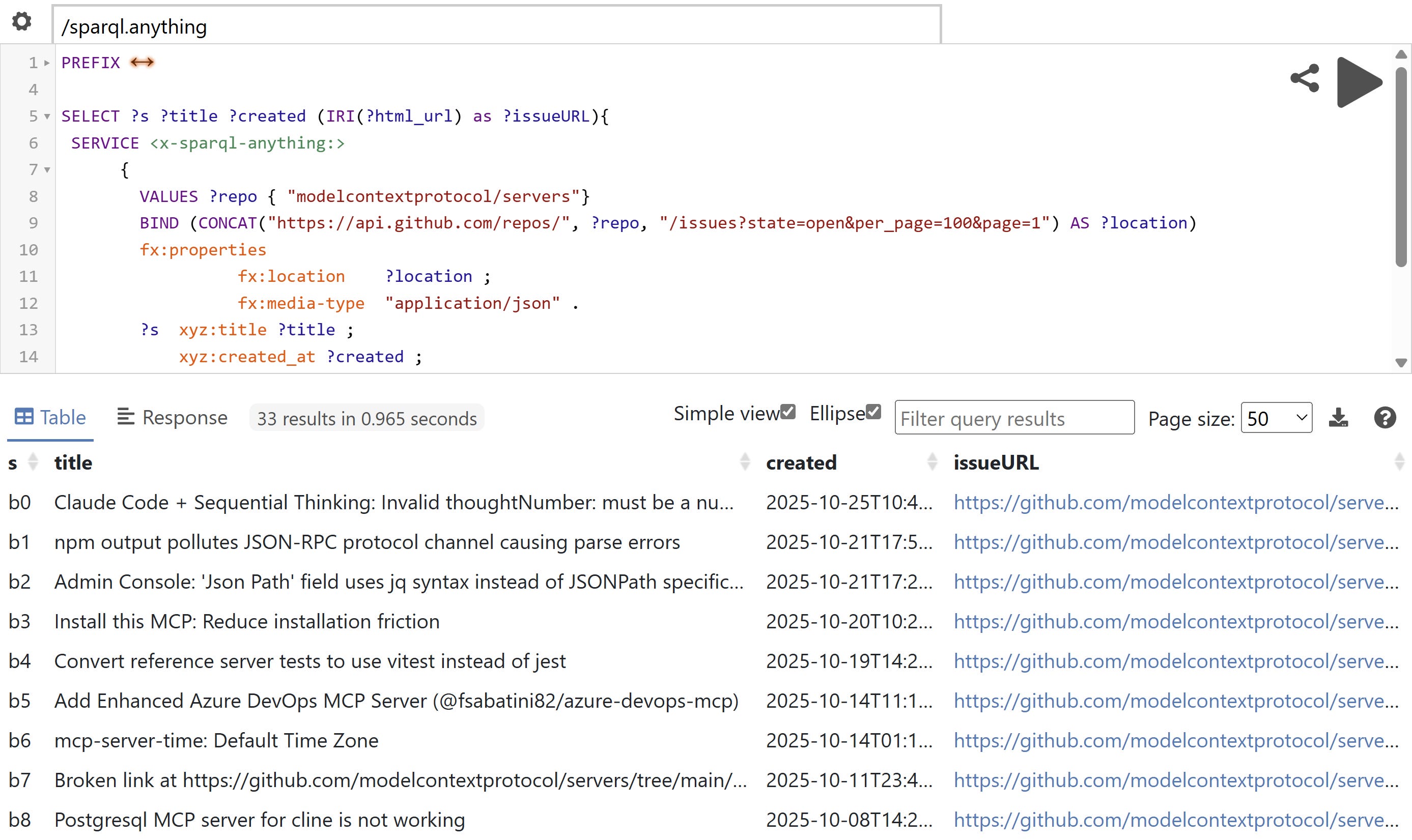
So, going back to what I started with in Part 1:
The problem comes when you need to answer a question, where parts of the answer are scattered across heterogeneous data sources. One part of the answer may happen to be in a JSON file, served from an API, another is in an Excel workbook, stored in your drive, and yet others are in Microsoft Word, CSV and XML.
Now, in one query, one SERVICE clause can direct part of the query to a local MS Word file, another to a CSV file on the web and a third, to some API, not even counting the trivial case of querying conventional SPARQL endpoints.
One real use case when SPARQL Anything saved me lot of time was when I was reviewing a project deliverable with data quality rules, each based on a property from a domain ontology that gave semantics to the graph the rules were designed for.
These rules were put in a table, and tables can be neatly triplified by constructing a property from the column literal. The subject is the row, the predicate is the constructed URI from the column label, and the object is whatever is in the respective cell.
Here’s a generalized version of that federated query:
SELECT DISTINCT ?ep
WHERE {
SERVICE <x-sparql-anything:> # calls the remote ontology file
{ fx:properties
fx:location “http://example.org/ontology.ttl”;
fx:media-type “text/turtle” .
{ ?ep rdf:type owl:ObjectProperty . } UNION
{ ?ep rdf:type owl:DatatypeProperty . }
}
FILTER NOT EXISTS {
SERVICE <x-sparql-anything:> #calls the local MS Word file
{ fx:properties
fx:location “file:///C:/example.docx” ;
fx:media-type “application/vnd.openxmlformats-officedocument.wordprocessingml.document” ;
fx:docs.table-headers true ; #tells the engine to cretae proeprties from the table headers
.
?s ?p [xyz:Property ?epQ] # In case the column of interest is with header “Property”
}
FILTER CONTAINS (STR(?epQ), STR(?ep))
}
}
The future of Façade-X
At the moment of writing, SPARQL Anything, the reference implementation of Façade-X, can support the following formats: XML, JSON, CSV, HTML, Excel, Text, Binary, EXIF, File System, Zip/Tar, Markdown, YAML, Bibtex, DOCx, PPTX. Here you can check out the documentation of each format. One data source still not officially supported is SQL, but that will come in the future. Until then, there is a workaround.
Recently, a W3C community group for Data Façades was created, to standardize and further develop the Façade-X and allow for other implementations besides the current SPARQL Anything.
A step-by-step tutorial
There are already some good tutorials on the website of SPARQL Anything. But if you’d like to reproduce the examples from these two posts, here’s a step-by-step guide which you can follow without knowing SPARQL.
